
Genetic Algorithm
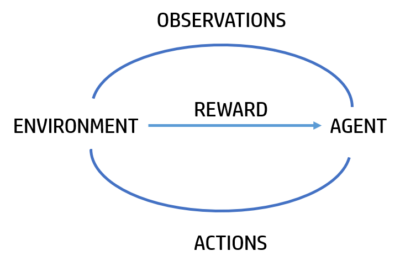
Genetic algorithm (GA) is a type of reinforcement learning inspired in the Universal Law of Evolution of Darwin. It can be easily used with neural networks where the genetic algorithm is the learning process of the Neural Network. It has a lot of uses for Artificial Intelligence problems that requires complex solution. I have used it for a snake environment where they need to survive and also eat for not dying and also for Self Driving Autonomous Cars in a 3D Environment.
The idea of this algorithm is to create the best agents in an specific environment. Each agent will perform actions depending on its neural network configuration and the environment will analyze it and score it with the fitness function. If the score is high it will give better rewards to the agents in this case, transmit some parts of its DNA to the next generation agents.
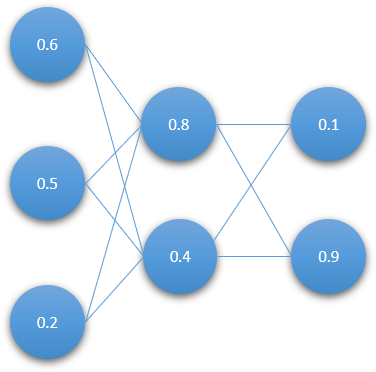
The neural networks weights are the connections of the neurons to the next layer neurons. They store a decimal value that in this case all the ways constitue the DNA of the agent or entity.
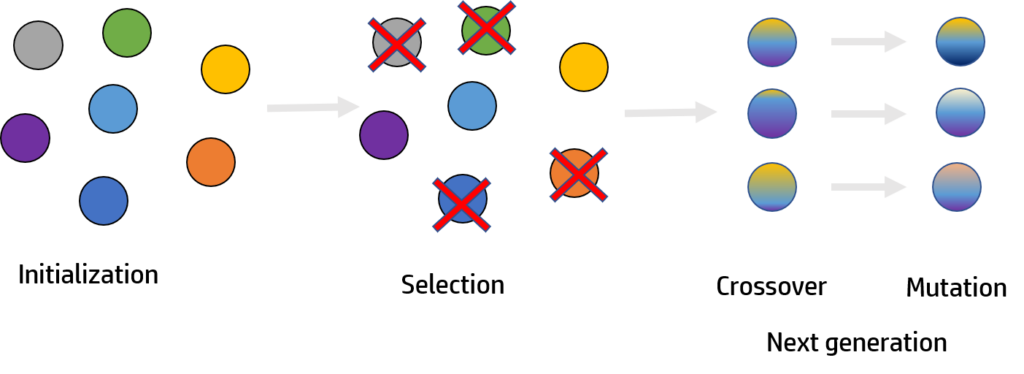
The process of learning of the genetic algorithm can be subdivided in different subprocesses:
- Initialize all the neural networks of the new agents (weights – DNA). If it’s the first generation all the weights will be random [-1,1].
- Selection: with an specific fitness function we will select the best survivors of the environment depending on their behavior.
- Crossover: on each new agent we will crossover the DNAs of the selected survivors.
- Mutation: some values will be randomly updated to get new unexpected behaviors that could improve the behavior of the agent.
Initialization
All the entities in a generation will be initialized. If the generation is the first, the neural networks will have random weights between [0-1] and also the DNA will be identical to this weights.
Selection
During the simulation the entities will take actions depending on its DNA (weights) when the neural networks is updated with the feed-forward function. When we want to start a new generation we will compute the accuracy of each agent depending on the distance travelled, time survived. We also need to calculate the diversity that will depend on the DNA differences and consequently in their behaviors.
Finally to get the fitness value of an entity we will need to calculate it depending on the diversity and accuracy with a selection rate of the importance of the diversity
fitness=k · diversity + (1-k) · accuracy
When we calculate all the agent’s fitness we will be able to get the entities with the best fitness and perform the DNA manipulation.
Crossover
With the winner DNAs we will swap some fragments to create a new DNA that shares parts of each parent. Each child (new agent), will have different DNAs. The length of the fragments will be random and will depend on the crossover rate. It will give important to the order of the best fitnesses or not.

In the image the first DNA is the first winner (most fitness) and the second DNA the second winner. The third DNA is the crossovered DNA of a new agent of the next generation.
Mutation
To create new agents that can have different behaviors from the parents we will do little mutations to the DNA. This probability of mutation will be inversily proportional to the total fitness of the previous generation.

The first DNA is the crossovered that we will be mutating. The second is the mutated DNA.
New generations
The idea is to create new generations when the previous has finished or when we want to evolve. When the generation count increases better entities will be created and the DNA will improve and the agents will survive more time.
If you want to put in practice this concepts you can watch my tutorial series of how to create a Self Driving Car Simulator
Pingback: Autonomous Driving Simulation - dDev Tech Tutorials - Retopall
Pingback: Self Driving Cars Archives – dDev Tech Tutorials – 24LINE.NET